
Ziang Cao
Ph.D student
Nanyang Technological University
CV
SocialInterests
Deep learning, Robotics, Computer vision.
About me
Ziang Cao is currently a Second-year PhD student in the College of Computer and Data Science in Nanyang Technological Unviersity, with MMLab@NTU, supervised by Prof. Ziwei Liu. His research interests lie on the computer vision, deep learning, and 3D generation.
News
[Apr. 2026] Invited talk at China3DV and awarded Rising Star Award.
[Apr. 2026] PhysX-Anything is selected as one of the Top-5 Papers at China3DV.
[Feb. 2026] One paper (PhysX-Anything) is accepted by CVPR 2026.
[Oct. 2025] I am awarded Google PhD Fellowship 2025 (Machine Perception).
[Sep. 2025] One paper (PhysX-3D) is accepted by NeurIPS 2025 as Spotlight.
[Feb. 2025] One paper (3DTopia-XL) is accepted by CVPR2025 as Highlight.
[May. 2024] One paper (DiffTF++) is accepted by TPAMI.
[Jan. 2024] One paper (DiffTF) is accepted by ICLR.
[Aug. 2023] One paper (TCTrack++ ) is accepted by TPAMI.
[Mar. 2022] Two papers (TCTrack and EgoPAT3D) are accepted by CVPR2022.
[Feb. 2022] One paper is accepted by RA-L2022.
[Feb. 2022] One paper is accepted by ICRA2022.
[Aug. 2021] One paper (HiFT) is accepted by ICCV2021.
[July. 2021] Two papers (SiamAPN++ and DarkLighter ) are accepted by IROS2021.
[May. 2021] One paper is accepted by TGRS.
[Feb. 2021] One paper is accepted by ICRA2021.
Selected Publications

PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Ziang Cao, Fangzhou Hong, Zhaoxi Chen, Liang Pan, Ziwei Liu. CVPR 2026.
3D modeling is shifting from static visual representations toward physical, articulated assets that can be directly
used in simulation and interaction. However, most existing
3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything,
the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose
the first VLM-based physical 3D generative model, along
with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM to-
ken budgets without introducing any special tokens during
fine-tuning and significantly improving generative quality.
In addition, to overcome the limited diversity of existing
physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior phys-
ical 3D datasets by over 2x and includes more than 2K
common real-world objects with rich physical annotations.
Extensive experiments on PhysX-Mobility and in-the-wild
images demonstrate that PhysX-Anything delivers strong
generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style
environment validate that our sim-ready assets can be di-
rectly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad
range of downstream applications, especially in embodied
AI and physics-based simulation

PhysX-3D: Physical-Grounded 3D Asset Generation
Ziang Cao, Zhaoxi Chen, Liang Pan, Ziwei Liu. NeurIPS 2025, Spotlight.
3D modeling is moving from virtual to physical. Existing 3D generation primarily emphasizes geometries and textures while neglecting physical-grounded modeling. Consequently, despite the rapid development of 3D generative models, the synthesized 3D assets often overlook rich and important physical properties, hampering their real-world application in physical domains like simulation and embodied AI. As an initial attempt to address this challenge, we propose \textbf{PhysX-3D}, an end-to-end paradigm for physical-grounded 3D asset generation. 1) To bridge the critical gap in physics-annotated 3D datasets, we present PhysXNet - the first physics-grounded 3D dataset systematically annotated across five foundational dimensions: absolute scale, material, affordance, kinematics, and function description. In particular, we devise a scalable human-in-the-loop annotation pipeline based on vision-language models, which enables efficient creation of physics-first assets from raw 3D assets.2) Furthermore, we propose \textbf{PhysXGen}, a feed-forward framework for physics-grounded image-to-3D asset generation, injecting physical knowledge into the pre-trained 3D structural space. Specifically, PhysXGen employs a dual-branch architecture to explicitly model the latent correlations between 3D structures and physical properties, thereby producing 3D assets with plausible physical predictions while preserving the native geometry quality. Extensive experiments validate the superior performance and promising generalization capability of our framework. All the code, data, and models will be released to facilitate future research in generative physical AI.
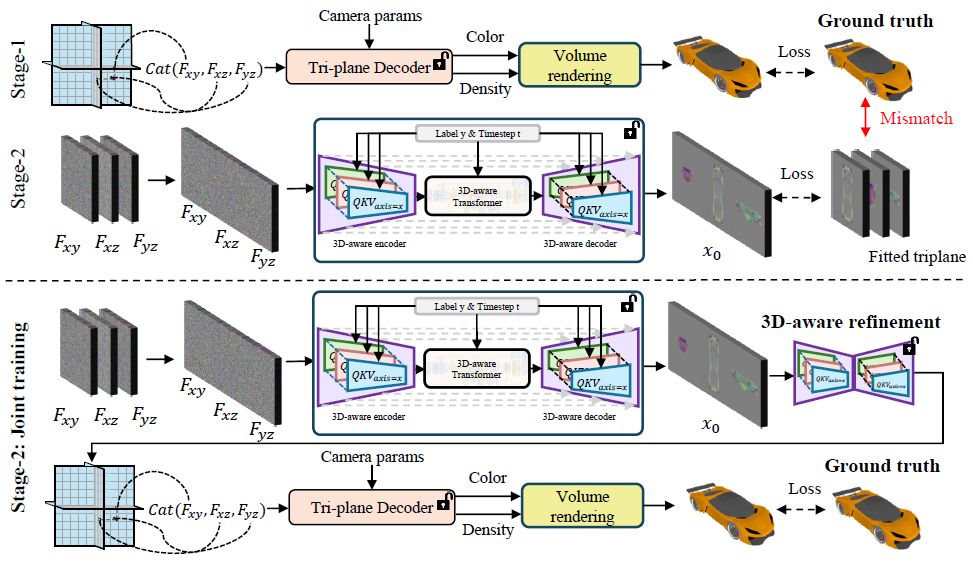
DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu. TPAMI.
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.

Large-Vocabulary 3D Diffusion Model with Transformer
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu. ICLR 2024.
Creating diverse and high-quality 3D assets with an automatic generative model is
highly desirable. Despite extensive efforts on 3D generation, most existing works
focus on the generation of a single category or a few categories. In this paper,
we introduce a diffusion-based feed-forward framework for synthesizing massive
categories of real-world 3D objects with a single generative model. Notably, there
are three major challenges for this large-vocabulary 3D generation: a) the need
for expressive yet efficient 3D representation; b) large diversity in geometry and
texture across categories; c) complexity in the appearances of real-world objects.
To this end, we propose a novel triplane-based 3D-aware Diffusion model with
TransFormer, DiffTF, for handling challenges via three aspects. 1) Considering
efficiency and robustness, we adopt a revised triplane representation and improve
the fitting speed and accuracy. 2) To handle the drastic variations in geometry and
texture, we regard the features of all 3D objects as a combination of generalized
3D knowledge and specialized 3D features. To extract generalized 3D knowledge
from diverse categories, we propose a novel 3D-aware transformer with shared
cross-plane attention. It learns the cross-plane relations across different planes
and aggregates the generalized 3D knowledge with specialized 3D features. 3)
In addition, we devise the 3D-aware encoder/decoder to enhance the generalized
3D knowledge in the encoded triplanes for handling categories with complex
appearances. Extensive experiments on ShapeNet and OmniObject3D (over 200
diverse real-world categories) convincingly demonstrate that a single DiffTF model
achieves state-of-the-art large-vocabulary 3D object generation performance with
large diversity, rich semantics, and high quality. Our project page: https://
ziangcao0312.github.io/difftf_pages/.
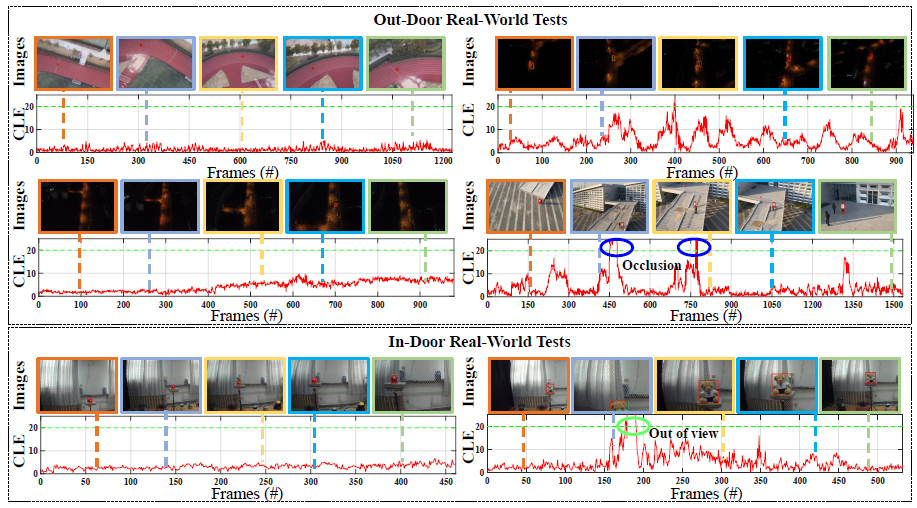
Towards Real-World Visual Tracking with Temporal Contexts
Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu. TPAMI.
Visual tracking has made significant improvements in the past few decades. Most existing state-of-the-art trackers 1) merely
aim for performance in ideal conditions while overlooking the real-world conditions; 2) adopt the tracking-by-detection paradigm,
neglecting rich temporal contexts; 3) only integrate the temporal information into the template, where temporal contexts among
consecutive frames are far from being fully utilized. To handle those problems, we propose a two-level framework (TCTrack) that can
exploit temporal contexts efficiently. Based on it, we propose a stronger version for real-world visual tracking, i.e., TCTrack++. It boils
down to two levels: features and similarity maps. Specifically, for feature extraction, we propose an attention-based temporally adaptive
convolution to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution
weights. For similarity map refinement, we introduce an adaptive temporal transformer to encode the temporal knowledge efficiently and
decode it for the accurate refinement of the similarity map. To further improve the performance, we additionally introduce a curriculum
learning strategy. Also, we adopt online evaluation to measure performance in real-world conditions. Exhaustive experiments on 8 wellknown
benchmarks demonstrate the superiority of TCTrack++. Real-world tests directly verify that TCTrack++ can be readily used in
real-world applications.

Egocentric Prediction of Action Target in 3D
Yiming Li*,Ziang Cao*, Andrew Liang, Benjamin Liang, Luoyao Chen, Hang Zhao, Chen Feng. CVPR 2022, * denotes equal contribution.
We are interested in anticipating as early as possible the target location of a person's object manipulation action in a 3D workspace from egocentric vision. It is important in fields like human-robot collaboration, but has not yet received enough attention from vision and learning communities. To stimulate more research on this challenging egocentric vision task, we propose a large multi-modal dataset of more than 1 million frames of RGBD and IMU streams, and provide evaluation metrics based on our high-quality 2D and 3D labels from semi-automatic annotation. Meanwhile, we design baseline methods using recurrent neural networks (RNNs) and conduct various ablation studies to validate their effectiveness. Our results demonstrate that this new task is worthy of further study by researchers in robotics, vision, and learning communities.
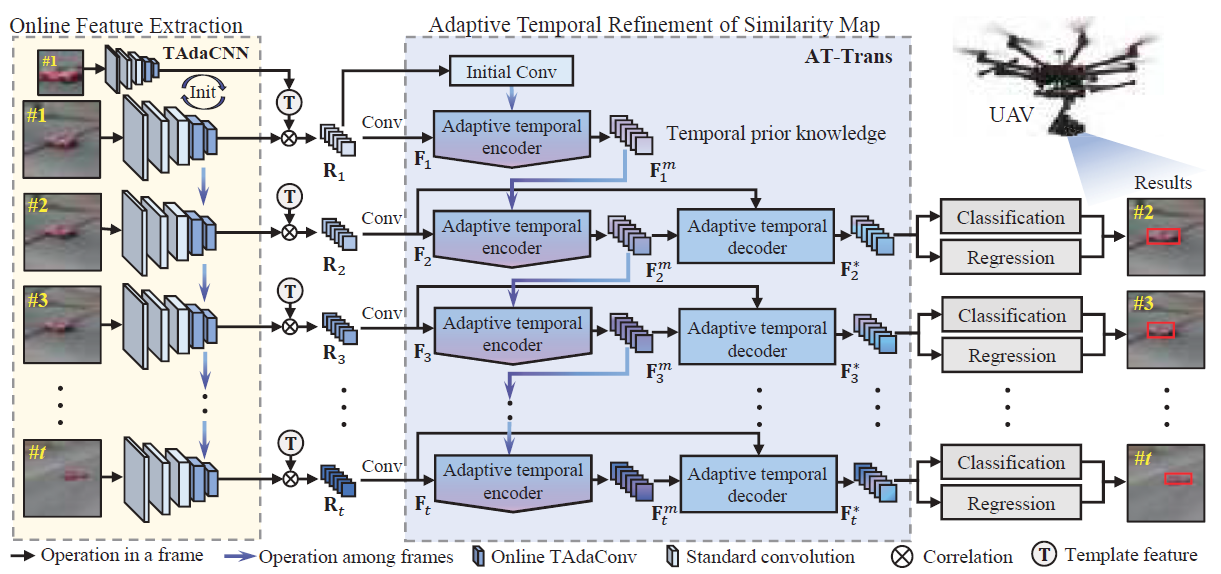
TCTrack: Temporal Contexts for Aerial Tracking
Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu. CVPR 2022.
Temporal contexts among consecutive frames are far from being fully utilized in existing visual trackers. In this work, we present TCTrack, a comprehensive framework to fully exploit temporal contexts for aerial tracking. The temporal contexts are incorporated at \textbf{two levels}: the extraction of \textbf{features} and the refinement of \textbf{similarity maps}. Specifically, for feature extraction, an online temporally adaptive convolution is proposed to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights according to the previous frames. For similarity map refinement, we propose an adaptive temporal transformer, which first effectively encodes temporal knowledge in a memory-efficient way, before the temporal knowledge is decoded for accurate adjustment of the similarity map. TCTrack is effective and efficient: evaluation on four aerial tracking benchmarks shows its impressive performance; real-world UAV tests show its high speed of over 27 FPS on NVIDIA Jetson AGX Xavier.
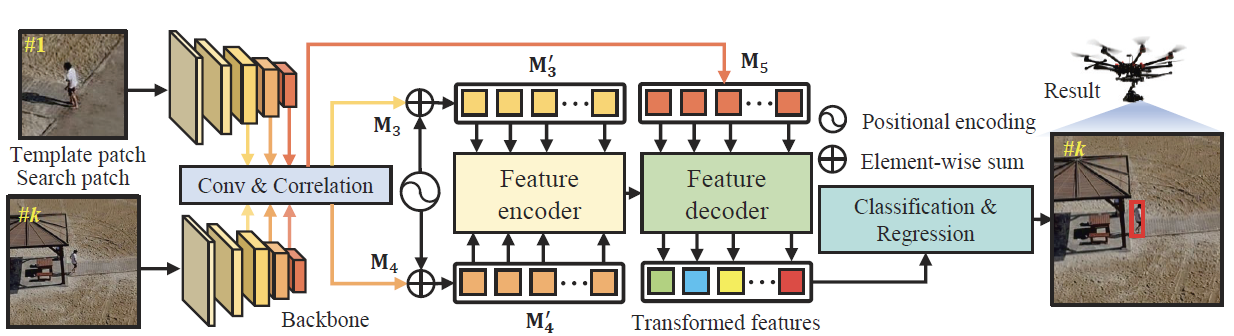
HiFT: Hierarchical Feature Transformer for Aerial Tracking
Ziang Cao, Changhong Fu, Junjie Ye, Bowen Li, Yiming Li. ICCV 2021.
Most existing Siamese-based tracking methods execute the classification and regression of the target object based on the similarity maps. However, they either employ a single map from the last convolutional layer which degrades the localization accuracy in complex scenarios or separately use multiple maps for decision making, introducing intractable computations for aerial mobile platforms. Thus, in this work, we propose an efficient and effective hierarchical feature transformer (HiFT) for aerial tracking. Hierarchical similarity maps generated by multi-level convolutional layers are fed into the feature transformer to achieve the interactive fusion of spatial (shallow layers) and semantics cues (deep layers). Consequently, not only the global contextual information can be raised, facilitating the target search, but also our end-to-end architecture with the transformer can efficiently learn the interdependencies among multi-level features, thereby discovering a tracking-tailored feature space with strong discriminability. Comprehensive evaluations on four aerial benchmarks have proven the effectiveness of HiFT. Real-world tests on the aerial platform have strongly validated its practicability with a real-time speed. Our code is available at https://github.com/vision4robotics/HiFT.
Awards & Scholarships
News
[Apr. 2026] Invited talk at China3DV and awarded Rising Star Award.
[Apr. 2026] PhysX-Anything is selected as one of the Top-5 Papers at China3DV.
[Feb. 2026] One paper (PhysX-Anything) is accepted by CVPR 2026.
[Oct. 2025] I am awarded Google PhD Fellowship 2025 (Machine Perception).
[Sep. 2025] One paper (PhysX-3D) is accepted by NeurIPS 2025 as Spotlight.
[Feb. 2025] One paper (3DTopia-XL) is accepted by CVPR2025 as Highlight.
[May. 2024] One paper (DiffTF++) is accepted by TPAMI.
[Jan. 2024] One paper (DiffTF) is accepted by ICLR.
[Aug. 2023] One paper (TCTrack++ ) is accepted by TPAMI.
[Mar. 2022] Two papers (TCTrack and EgoPAT3D) are accepted by CVPR2022.
[Feb. 2022] One paper is accepted by RA-L2022.
[Feb. 2022] One paper is accepted by ICRA2022.
[Aug. 2021] One paper (HiFT) is accepted by ICCV2021.
[July. 2021] Two papers (SiamAPN++ and DarkLighter ) are accepted by IROS2021.
[May. 2021] One paper is accepted by TGRS.
[Feb. 2021] One paper is accepted by ICRA2021.
Selected Publications
PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Ziang Cao, Fangzhou Hong, Zhaoxi Chen, Liang Pan, Ziwei Liu. CVPR 2026.
3D modeling is shifting from static visual representations toward physical, articulated assets that can be directly
used in simulation and interaction. However, most existing
3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything,
the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose
the first VLM-based physical 3D generative model, along
with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM to-
ken budgets without introducing any special tokens during
fine-tuning and significantly improving generative quality.
In addition, to overcome the limited diversity of existing
physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior phys-
ical 3D datasets by over 2x and includes more than 2K
common real-world objects with rich physical annotations.
Extensive experiments on PhysX-Mobility and in-the-wild
images demonstrate that PhysX-Anything delivers strong
generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style
environment validate that our sim-ready assets can be di-
rectly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad
range of downstream applications, especially in embodied
AI and physics-based simulation
PhysX-3D: Physical-Grounded 3D Asset Generation
Ziang Cao, Zhaoxi Chen, Liang Pan, Ziwei Liu. NeurIPS 2025, Spotlight.
3D modeling is moving from virtual to physical. Existing 3D generation primarily emphasizes geometries and textures while neglecting physical-grounded modeling. Consequently, despite the rapid development of 3D generative models, the synthesized 3D assets often overlook rich and important physical properties, hampering their real-world application in physical domains like simulation and embodied AI. As an initial attempt to address this challenge, we propose \textbf{PhysX-3D}, an end-to-end paradigm for physical-grounded 3D asset generation. 1) To bridge the critical gap in physics-annotated 3D datasets, we present PhysXNet - the first physics-grounded 3D dataset systematically annotated across five foundational dimensions: absolute scale, material, affordance, kinematics, and function description. In particular, we devise a scalable human-in-the-loop annotation pipeline based on vision-language models, which enables efficient creation of physics-first assets from raw 3D assets.2) Furthermore, we propose \textbf{PhysXGen}, a feed-forward framework for physics-grounded image-to-3D asset generation, injecting physical knowledge into the pre-trained 3D structural space. Specifically, PhysXGen employs a dual-branch architecture to explicitly model the latent correlations between 3D structures and physical properties, thereby producing 3D assets with plausible physical predictions while preserving the native geometry quality. Extensive experiments validate the superior performance and promising generalization capability of our framework. All the code, data, and models will be released to facilitate future research in generative physical AI.
DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu. TPAMI.
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
Large-Vocabulary 3D Diffusion Model with Transformer
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu. ICLR 2024.
Creating diverse and high-quality 3D assets with an automatic generative model is
highly desirable. Despite extensive efforts on 3D generation, most existing works
focus on the generation of a single category or a few categories. In this paper,
we introduce a diffusion-based feed-forward framework for synthesizing massive
categories of real-world 3D objects with a single generative model. Notably, there
are three major challenges for this large-vocabulary 3D generation: a) the need
for expressive yet efficient 3D representation; b) large diversity in geometry and
texture across categories; c) complexity in the appearances of real-world objects.
To this end, we propose a novel triplane-based 3D-aware Diffusion model with
TransFormer, DiffTF, for handling challenges via three aspects. 1) Considering
efficiency and robustness, we adopt a revised triplane representation and improve
the fitting speed and accuracy. 2) To handle the drastic variations in geometry and
texture, we regard the features of all 3D objects as a combination of generalized
3D knowledge and specialized 3D features. To extract generalized 3D knowledge
from diverse categories, we propose a novel 3D-aware transformer with shared
cross-plane attention. It learns the cross-plane relations across different planes
and aggregates the generalized 3D knowledge with specialized 3D features. 3)
In addition, we devise the 3D-aware encoder/decoder to enhance the generalized
3D knowledge in the encoded triplanes for handling categories with complex
appearances. Extensive experiments on ShapeNet and OmniObject3D (over 200
diverse real-world categories) convincingly demonstrate that a single DiffTF model
achieves state-of-the-art large-vocabulary 3D object generation performance with
large diversity, rich semantics, and high quality. Our project page: https://
ziangcao0312.github.io/difftf_pages/.
Towards Real-World Visual Tracking with Temporal Contexts
Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu. TPAMI.
Visual tracking has made significant improvements in the past few decades. Most existing state-of-the-art trackers 1) merely
aim for performance in ideal conditions while overlooking the real-world conditions; 2) adopt the tracking-by-detection paradigm,
neglecting rich temporal contexts; 3) only integrate the temporal information into the template, where temporal contexts among
consecutive frames are far from being fully utilized. To handle those problems, we propose a two-level framework (TCTrack) that can
exploit temporal contexts efficiently. Based on it, we propose a stronger version for real-world visual tracking, i.e., TCTrack++. It boils
down to two levels: features and similarity maps. Specifically, for feature extraction, we propose an attention-based temporally adaptive
convolution to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution
weights. For similarity map refinement, we introduce an adaptive temporal transformer to encode the temporal knowledge efficiently and
decode it for the accurate refinement of the similarity map. To further improve the performance, we additionally introduce a curriculum
learning strategy. Also, we adopt online evaluation to measure performance in real-world conditions. Exhaustive experiments on 8 wellknown
benchmarks demonstrate the superiority of TCTrack++. Real-world tests directly verify that TCTrack++ can be readily used in
real-world applications.
Egocentric Prediction of Action Target in 3D
Yiming Li*,Ziang Cao*, Andrew Liang, Benjamin Liang, Luoyao Chen, Hang Zhao, Chen Feng. CVPR 2022, * denotes equal contribution.
We are interested in anticipating as early as possible the target location of a person's object manipulation action in a 3D workspace from egocentric vision. It is important in fields like human-robot collaboration, but has not yet received enough attention from vision and learning communities. To stimulate more research on this challenging egocentric vision task, we propose a large multi-modal dataset of more than 1 million frames of RGBD and IMU streams, and provide evaluation metrics based on our high-quality 2D and 3D labels from semi-automatic annotation. Meanwhile, we design baseline methods using recurrent neural networks (RNNs) and conduct various ablation studies to validate their effectiveness. Our results demonstrate that this new task is worthy of further study by researchers in robotics, vision, and learning communities.
TCTrack: Temporal Contexts for Aerial Tracking
Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu. CVPR 2022.
Temporal contexts among consecutive frames are far from being fully utilized in existing visual trackers. In this work, we present TCTrack, a comprehensive framework to fully exploit temporal contexts for aerial tracking. The temporal contexts are incorporated at \textbf{two levels}: the extraction of \textbf{features} and the refinement of \textbf{similarity maps}. Specifically, for feature extraction, an online temporally adaptive convolution is proposed to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights according to the previous frames. For similarity map refinement, we propose an adaptive temporal transformer, which first effectively encodes temporal knowledge in a memory-efficient way, before the temporal knowledge is decoded for accurate adjustment of the similarity map. TCTrack is effective and efficient: evaluation on four aerial tracking benchmarks shows its impressive performance; real-world UAV tests show its high speed of over 27 FPS on NVIDIA Jetson AGX Xavier.
HiFT: Hierarchical Feature Transformer for Aerial Tracking
Ziang Cao, Changhong Fu, Junjie Ye, Bowen Li, Yiming Li. ICCV 2021.
Most existing Siamese-based tracking methods execute the classification and regression of the target object based on the similarity maps. However, they either employ a single map from the last convolutional layer which degrades the localization accuracy in complex scenarios or separately use multiple maps for decision making, introducing intractable computations for aerial mobile platforms. Thus, in this work, we propose an efficient and effective hierarchical feature transformer (HiFT) for aerial tracking. Hierarchical similarity maps generated by multi-level convolutional layers are fed into the feature transformer to achieve the interactive fusion of spatial (shallow layers) and semantics cues (deep layers). Consequently, not only the global contextual information can be raised, facilitating the target search, but also our end-to-end architecture with the transformer can efficiently learn the interdependencies among multi-level features, thereby discovering a tracking-tailored feature space with strong discriminability. Comprehensive evaluations on four aerial benchmarks have proven the effectiveness of HiFT. Real-world tests on the aerial platform have strongly validated its practicability with a real-time speed. Our code is available at https://github.com/vision4robotics/HiFT.
Awards & Scholarships
Selected Publications
PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Ziang Cao, Fangzhou Hong, Zhaoxi Chen, Liang Pan, Ziwei Liu. CVPR 2026.
3D modeling is shifting from static visual representations toward physical, articulated assets that can be directly used in simulation and interaction. However, most existing 3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything, the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose the first VLM-based physical 3D generative model, along with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM to- ken budgets without introducing any special tokens during fine-tuning and significantly improving generative quality. In addition, to overcome the limited diversity of existing physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior phys- ical 3D datasets by over 2x and includes more than 2K common real-world objects with rich physical annotations. Extensive experiments on PhysX-Mobility and in-the-wild images demonstrate that PhysX-Anything delivers strong generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style environment validate that our sim-ready assets can be di- rectly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad range of downstream applications, especially in embodied AI and physics-based simulation
PhysX-3D: Physical-Grounded 3D Asset Generation
Ziang Cao, Zhaoxi Chen, Liang Pan, Ziwei Liu. NeurIPS 2025, Spotlight.
3D modeling is moving from virtual to physical. Existing 3D generation primarily emphasizes geometries and textures while neglecting physical-grounded modeling. Consequently, despite the rapid development of 3D generative models, the synthesized 3D assets often overlook rich and important physical properties, hampering their real-world application in physical domains like simulation and embodied AI. As an initial attempt to address this challenge, we propose \textbf{PhysX-3D}, an end-to-end paradigm for physical-grounded 3D asset generation. 1) To bridge the critical gap in physics-annotated 3D datasets, we present PhysXNet - the first physics-grounded 3D dataset systematically annotated across five foundational dimensions: absolute scale, material, affordance, kinematics, and function description. In particular, we devise a scalable human-in-the-loop annotation pipeline based on vision-language models, which enables efficient creation of physics-first assets from raw 3D assets.2) Furthermore, we propose \textbf{PhysXGen}, a feed-forward framework for physics-grounded image-to-3D asset generation, injecting physical knowledge into the pre-trained 3D structural space. Specifically, PhysXGen employs a dual-branch architecture to explicitly model the latent correlations between 3D structures and physical properties, thereby producing 3D assets with plausible physical predictions while preserving the native geometry quality. Extensive experiments validate the superior performance and promising generalization capability of our framework. All the code, data, and models will be released to facilitate future research in generative physical AI.
DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu. TPAMI.
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
Large-Vocabulary 3D Diffusion Model with Transformer
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu. ICLR 2024.
Creating diverse and high-quality 3D assets with an automatic generative model is highly desirable. Despite extensive efforts on 3D generation, most existing works focus on the generation of a single category or a few categories. In this paper, we introduce a diffusion-based feed-forward framework for synthesizing massive categories of real-world 3D objects with a single generative model. Notably, there are three major challenges for this large-vocabulary 3D generation: a) the need for expressive yet efficient 3D representation; b) large diversity in geometry and texture across categories; c) complexity in the appearances of real-world objects. To this end, we propose a novel triplane-based 3D-aware Diffusion model with TransFormer, DiffTF, for handling challenges via three aspects. 1) Considering efficiency and robustness, we adopt a revised triplane representation and improve the fitting speed and accuracy. 2) To handle the drastic variations in geometry and texture, we regard the features of all 3D objects as a combination of generalized 3D knowledge and specialized 3D features. To extract generalized 3D knowledge from diverse categories, we propose a novel 3D-aware transformer with shared cross-plane attention. It learns the cross-plane relations across different planes and aggregates the generalized 3D knowledge with specialized 3D features. 3) In addition, we devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge in the encoded triplanes for handling categories with complex appearances. Extensive experiments on ShapeNet and OmniObject3D (over 200 diverse real-world categories) convincingly demonstrate that a single DiffTF model achieves state-of-the-art large-vocabulary 3D object generation performance with large diversity, rich semantics, and high quality. Our project page: https:// ziangcao0312.github.io/difftf_pages/.
Towards Real-World Visual Tracking with Temporal Contexts
Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu. TPAMI.
Visual tracking has made significant improvements in the past few decades. Most existing state-of-the-art trackers 1) merely aim for performance in ideal conditions while overlooking the real-world conditions; 2) adopt the tracking-by-detection paradigm, neglecting rich temporal contexts; 3) only integrate the temporal information into the template, where temporal contexts among consecutive frames are far from being fully utilized. To handle those problems, we propose a two-level framework (TCTrack) that can exploit temporal contexts efficiently. Based on it, we propose a stronger version for real-world visual tracking, i.e., TCTrack++. It boils down to two levels: features and similarity maps. Specifically, for feature extraction, we propose an attention-based temporally adaptive convolution to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights. For similarity map refinement, we introduce an adaptive temporal transformer to encode the temporal knowledge efficiently and decode it for the accurate refinement of the similarity map. To further improve the performance, we additionally introduce a curriculum learning strategy. Also, we adopt online evaluation to measure performance in real-world conditions. Exhaustive experiments on 8 wellknown benchmarks demonstrate the superiority of TCTrack++. Real-world tests directly verify that TCTrack++ can be readily used in real-world applications.
Egocentric Prediction of Action Target in 3D
Yiming Li*,Ziang Cao*, Andrew Liang, Benjamin Liang, Luoyao Chen, Hang Zhao, Chen Feng. CVPR 2022, * denotes equal contribution.
We are interested in anticipating as early as possible the target location of a person's object manipulation action in a 3D workspace from egocentric vision. It is important in fields like human-robot collaboration, but has not yet received enough attention from vision and learning communities. To stimulate more research on this challenging egocentric vision task, we propose a large multi-modal dataset of more than 1 million frames of RGBD and IMU streams, and provide evaluation metrics based on our high-quality 2D and 3D labels from semi-automatic annotation. Meanwhile, we design baseline methods using recurrent neural networks (RNNs) and conduct various ablation studies to validate their effectiveness. Our results demonstrate that this new task is worthy of further study by researchers in robotics, vision, and learning communities.
TCTrack: Temporal Contexts for Aerial Tracking
Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu. CVPR 2022.
Temporal contexts among consecutive frames are far from being fully utilized in existing visual trackers. In this work, we present TCTrack, a comprehensive framework to fully exploit temporal contexts for aerial tracking. The temporal contexts are incorporated at \textbf{two levels}: the extraction of \textbf{features} and the refinement of \textbf{similarity maps}. Specifically, for feature extraction, an online temporally adaptive convolution is proposed to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights according to the previous frames. For similarity map refinement, we propose an adaptive temporal transformer, which first effectively encodes temporal knowledge in a memory-efficient way, before the temporal knowledge is decoded for accurate adjustment of the similarity map. TCTrack is effective and efficient: evaluation on four aerial tracking benchmarks shows its impressive performance; real-world UAV tests show its high speed of over 27 FPS on NVIDIA Jetson AGX Xavier.
HiFT: Hierarchical Feature Transformer for Aerial Tracking
Ziang Cao, Changhong Fu, Junjie Ye, Bowen Li, Yiming Li. ICCV 2021.
Most existing Siamese-based tracking methods execute the classification and regression of the target object based on the similarity maps. However, they either employ a single map from the last convolutional layer which degrades the localization accuracy in complex scenarios or separately use multiple maps for decision making, introducing intractable computations for aerial mobile platforms. Thus, in this work, we propose an efficient and effective hierarchical feature transformer (HiFT) for aerial tracking. Hierarchical similarity maps generated by multi-level convolutional layers are fed into the feature transformer to achieve the interactive fusion of spatial (shallow layers) and semantics cues (deep layers). Consequently, not only the global contextual information can be raised, facilitating the target search, but also our end-to-end architecture with the transformer can efficiently learn the interdependencies among multi-level features, thereby discovering a tracking-tailored feature space with strong discriminability. Comprehensive evaluations on four aerial benchmarks have proven the effectiveness of HiFT. Real-world tests on the aerial platform have strongly validated its practicability with a real-time speed. Our code is available at https://github.com/vision4robotics/HiFT.
Awards & Scholarships
Awards & Scholarships
[2026] China3DV Rising Star Award.
[2025] Google PhD Fellowship.
[2023] Champion solution in OmniObject3D Challenge @ ICCV 2023 Champion design.
[2022] Excellent undergraduate student of shanghai.
[2021] Research star of Tongji.
[2021] Baosteel Scholarship (top 0.5%).
[2020] National Scholarship (top 1%).
[2019] Honda China ECO-Mileage Challenge Champion design.
[2019] National Scholarship (top 1%).
[2018] Second Prize of Chinese undergraduate advanced mathematics competition.
[2018] National Scholarship (top 1%).
Education & Experiences
Education & Experiences
Education & Experiences
[Sep. 2017-Jun. 2022] Tonji University , Vehicle Engineering, Shanghai, China.
[Jun. 2022-Feb. 2023] Shanghai Artificial Intelligence Laboratory , Shanghai, China.
[Feb. 2023-Present] Nanyang Technological University , Singapore.